It is remarkable that a science which began with the consideration of games of chance should have become the most important object of human knowledge. Laplace, Pierre Simon, 1812
Life is about making decisions under uncertainty. We always prefer informed decisions Statistical decision theory studies the process of finding a reasonable course of action when faced with statistical uncertainty–uncertainty that can in part be quantified from observed data. In most cases, the problem can be separated into two problems: a learning problem or parameter estimation problem and then a decision problem that uses the output of the learning problem. In finance, a classic example of this is finding optimal portfolios with a mean-variance utility/criterion function assuming the underlying means, variances and covariances are unknown based on a historical sample of data. In statistics, the classic problem is using decision theory to evaluate the relative merits of different parameter estimators hypothesis tests.
To a Bayesian, the solution to these decision problems are rather obvious: compute posterior distributions, and then make decisions by maximizing expected utility, where the posterior distribution is used to calculate the expectations. Classical solutions to these problems are different, and use repeated sampling ideas, whereby the performance of a decision rule is judged on its performance if the same decision problem were repeated infinitely. Thus, the decisions are made based on their population properties. One of the main uses of statistical decision theory is to compare different estimators or hypothesis testing procedures. This theory generates many important findings, most notably that many of the common classical estimators are “bad”,in some sense, and that Bayesian estimators are always “good”.
These results have major implications for empirical work and practical applications, as they provide a guide for forecasting.
5.1 Statistical Decisions and Risk
The statistical decision making problem can be posed as follows. A decision maker (you) has to chose from a set of decisions or acts. The consequences of these decisions depend on an unknown state of the world. Let \(d\in\mathcal{D}\) denote the decision and \(\theta\in\Theta\) the state of the world. As an example, think of \(\theta\) as the unknown parameter and the decision as choosing a parameter estimation or hypothesis testing procedure. To provide information about the parameter, the decision maker obtains a sample \(y\in\mathcal{Y}\) that is generated from the likelihood function \(p\left(y|\theta\right)\). The resulting decision depends on the observed data, is denoted as \(d\left( y\right)\), and is commonly called the decision rule.
To make the decision, the decision maker uses a “loss” function as a quantitative metric to assesses the consequences or performance of different decisions. For each state of the world \(\theta\), and decision \(d\), \(L\left( \theta,d\right)\) quantifies the “loss” made by choosing \(d\) when the state of the world is \(\theta.\) Common loss functions include a quadratic loss, \(L(\theta,d)=(\theta-d)^{2},\) an absolute loss, \(L(\theta,d)=|\theta-d|\), and a \(0-1\) loss, \[
L(\theta,d)=L_{0}1_{\left[ \theta\in\Theta_{0}\right] }+L_{1}1_{\left[ \theta\in\Theta_{1}\right] }.
\] For Bayesians, the utility function provides a natural loss function. Historically, decision theory was developed by classical statisticians, thus the development in terms of “objective” loss functions instead of “subjective” utility.
Classical decision theory takes a frequentist approach, treating parameters as `fixed but unknown’ and evaluating decisions based on their population properties. Intuitively, this thought experiment entails drawing a dataset \(y\) of given length and applying the same decision rule in a large number of repeated trials and averaging the resulting loss across those hypothetical samples. Formally, the classical risk function is defined as% \[
R(\theta,d)=\int_{\mathcal{Y}}L\left[ \theta,d(y)\right] p(y|\theta )dy=\mathbb{E}\left[ L\left[ \theta,d(y)\right] |\theta\right] .
\] Since the risk function integrates over the data, it does not depend on a given observed sample and is therefore an ex-ante or a-priori metric. In the case of quadratic loss, the risk function is the mean-squared error (MSE) and is% \[\begin{align*}
R(\theta,d) & =\int_{\mathcal{Y}}\left[ \theta-d\left( y\right) \right]
^{2}p(y|\theta)dy\\
& =\mathbb{E}\left[ \left( d\left( y\right) -E\left[ d\left( y\right)
|\theta\right] \right) ^{2}|\theta\right] +\mathbb{E}\left[ \left(
E\left[ d\left( y\right) |\theta\right] -\theta\right) ^{2}|\theta\right]
\\
& =var\left( d\left( y\right) |\theta\right) +\left[ bias\left(
d\left( y\right) -\theta\right) \right] ^{2}%
\end{align*}\] which can be interpreted as the bias of the decision/estimator plus the variance of the decision/estimator. Common frequentist estimators choose unbiased estimators so that the bias term is zero, which in most settings leads to unique estimators.
The goal of the decision maker is to minimize risk. Unfortunately, rarely is there a decision that minimizes risk uniformly for all parameter values. To see this, consider a simple example of \(y\sim N\left( \theta,1\right)\), a quadratic loss, and two decision rules, \(d_{1}\left( y\right) =0\) or \(d_{2}\left( y\right) =y\). Then, \(R\left( \theta,d_{1}\right) =\theta^{2}\) and \(R\left( \theta,d_{2}\right) =1\). If \(\left\vert \theta\right\vert <1\), then \(R\left( \theta,d_{1}\right) <R\left( \theta,d_{2}\right)\), with the ordering reversed for \(\left\vert \theta\right\vert >1\). Thus, neither rule uniformly dominates the other.
One way to deal with the lack of uniform domination is to use the minimax principle: first maximize risk as function of \(\theta\), \[
\theta^{\ast}=\underset{\theta\in\Theta}{\arg\max}R(\theta,d)\text{,}%
\] and then minimize the resulting risk by choosing a decision: \[
d_{m}^{\ast}=\underset{d\in\mathcal{D}}{\arg\min}\left[ R(\theta^{\ast },d)\right] \text{.}%
\] The resulting decision is known as a minimax decision rule. The motivation for minimax is game theory, with the idea that the statistician chooses the best decision rule against the other player, mother nature, who chooses the worst parameter.
The Bayesian approach treats parameters as random and specifies both a likelihood and prior distribution, denoted here by \(\pi\left( \theta\right)\). The Bayesian decision maker recognizes that both the data and parameters are random, and accounts for both sources of uncertainty when calculating risk. The Bayes risk is defined as \[\begin{align*}
r(\pi,d) & =\int_{\mathcal{\Theta}}\int_{\mathcal{Y}}L\left[ \theta ,d(y)\right] p(y|\theta)\pi\left( \theta\right) dyd\theta\\
& =\int_{\mathcal{\Theta}}R(\theta,d)\pi\left( \theta\right) d\theta =\mathbb{E}_{\pi}\left[ R(\theta,d)\right] ,
\end{align*}\] and thus the Bayes risk is an average of the classical risk, with the expectation taken under the prior distribution. The Bayes decision rule minimizes expected risk: \[
d_{\pi}^{\ast}=\underset{d\in\mathcal{D}}{\arg\min}\text{ }r(\pi,d)\text{.}%
\] The classical risk of a Bayes decision rule is defined as \(R\left( \theta,d_{\pi}^{\ast}\right)\), where \(d_{\pi}^{\ast}\) does not depend on \(\theta\) or \(y\). Minimizing expected risk is consistent with maximizing posterior expected utility or, in this case, minimizing expected loss. Expected posterior risk is \[
r(\pi,d)=\int_{\mathcal{Y}}\left[ \int_{\mathcal{\Theta}}L\left[
\theta,d(y)\right] p(y|\theta)\pi\left( \theta\right) d\theta\right] dy,
\] where the term in the brackets is posterior expected loss. Minimizing posterior expected loss for every \(y\in\mathcal{Y},\) is clearly equivalent to minimizing posterior expected risk, provided it is possibility to interchange the order of integration.
The previous definitions did not explicitly state that the prior distribution was proper, that is, that \(\int_{\mathcal{\Theta}}\pi\left( \theta\right)d\theta=1\). In some applications and for some parameters, researchers may use priors that do not integrate, \(\int_{\Theta}\pi\left( \theta\right)d\theta=\infty\), commonly called improper priors. A generalized Bayes rule is one that minimizes \(r(\pi,d),\) where \(\pi\) is not necessarily a distribution, if such a rule exists. If \(r(\pi,d)<\infty\), then the mechanics of this rule is clear, although its meaning is less clear.
5.2 Expectation and Variance (Reward and Risk)
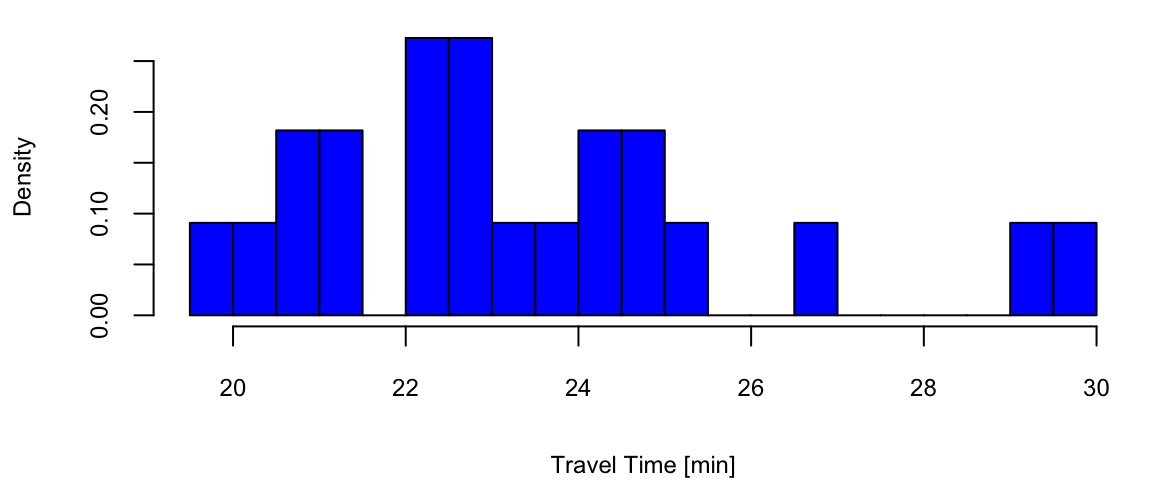
An expected value of a random variable, denoted by \(\E{X}\) is a weighted average. Each possible value of a random variable is weighted by its probability. For example, Google map uses expected value when calculating travel times. We might compute two different routes by their expected travel time. Typically, a forecast or expected value is all that is required — there expected values can be updated in real time as we travel. Say I am interested in travel time from Washington National airport to Fairfax in Virginia. The histogram below shows the travel times observed for a work day evening and were obtained from Uber.
Example 5.1 (Uber) Let’s look at the histogram of travel times from Fairfax, VA to Washington, DC
Code
d =read.csv("../../data/dc_travel_time.csv") # use eventing travel times (column 18) and convert from seconds to minutes evening_tt = d[,18]/60; day_tt = d[,15]/60; evening_tt = evening_tt[!is.na(evening_tt)] # remove missing observations hist(evening_tt, freq = F,main="", xlab="Travel Time [min]", nclass=20, col="blue")
Travel times in the evening
From this dataset, we can empirically estimate the probabilities of observing different values of travel times
Travel Time
Probability
18
0.05
22
0.77
28
0.18
There is a small chance (5%) I can get to Fairfax in 18 minutes, which probably happens on a holiday and a non-trivial chance (18%) to travel for 28 minutes, possibly due to a sports game or bad weather. Most of the times (77%) our travel time is 22 minutes. However, when Uber shows you the travel time, it uses the expected value as a forecast rather than the full distribution. Specifically, you will be given an expected travel of 23 minutes.
0.05*18+0.77*22+0.18*28
23
It is a simple summary takes into account travel accidents and other events that can effect travel time as best as it can.
The expected value \(\E{X}\) of discrete random variable \(X\) which takes possible values \(\{x_1,\ldots x_n\}\) is calculated using
\[
\E{X} =\sum_{i=1}^{n}x_i\prob{X = x_i}
\]
For example, in a binary scenario, if \(X\in \{0,1\}\) and \(P(X=1)=p\), then \(\E{X} = 0\times(1-p)+1\times p = p\). Expected value of a Bernoulli random variable is simply the probability of success. In many binary scenarios, probabilistic forecast is sufficient.
If \(X\) is continuous with probability distribution \(p(x)\), then we have to calculate the expectation as an integral \[
\E{X} = \int xp(x)d x = \ \text{ and } \int p(x)dx = 1.
\] When you have a random variable \(x\) that has a support that is non-negative (that is, the variable has nonzero density/probability for only positive values), you can use the following property: \[
E(X) = \int_0^\infty \left( 1 - F(x) \right) \,\mathrm{d}x,
\] where \(F(x)\) is the cumulative distribution function (CDF) of \(X\). The proof is as follows: \[
E(X) = \int_0^\infty \left( 1 - F(x) \right) \,\mathrm{d}x = \int_0^\infty \int_x^\infty f(y) \,\mathrm{d}y \,\mathrm{d}x = \int_0^\infty \int_0^y \,\mathrm{d}x f(y) \,\mathrm{d}y = \int_0^\infty y f(y) \,\mathrm{d}y,
\] where \(f(x)\) is the probability density function (PDF) of \(X\). Moreover \[
E(X) = \int_{0}^1 F^{-1}(p) \,\mathrm{d}p,
\] where \(F^{-1}(p)\) is the inverse CDF of \(X\). The proof is as follows: \[
E(X) = \int_{0}^1 F^{-1}(p) \,\mathrm{d}p = \int_{0}^1 \int_{-\infty}^{F^{-1}(p)} f(x) \,\mathrm{d}x \,\mathrm{d}p = \int_{-\infty}^{\infty} \int_{0}^{F(x)} \,\mathrm{d}p f(x) \,\mathrm{d}x = \int_{-\infty}^{\infty} x f(x) \,\mathrm{d}x.
\]
5.2.1 Standard Deviation and Covariance
Variance measures the spread of a random variable around its expected value \[
\Var{X} = \E{(X-\E{X})^2} = \sum_{i=1}^n (x_i-\mu)^2 \prob{X=x_i}dx.
\] In the continious case, we have \[
\Var{X} = \int_{-\infty}^\infty (x-\mu) ^2 p(x)dx,
\] where \(\mu = \mathbb{E}(X)=\int_{-\infty}^{\infty}p_X(x)dx\). The standard deviation is more convenient and is a square root of variance \(\sd{X} = \sqrt{\Var{X}}\). Standard deviation has the desirable property that it is measured in the same units as the random variable \(X\) itself and is a more useful measure.
Suppose that we have two random variables \(X\) and \(Y\). We need to measure whether they move together or in opposite directions. The covariance is defined by \[
\Cov{X,Y} = \E{\left[ X- \E{X})(Y- \E{Y}\right]}.
\]
When \(X\) and \(Y\) are discrete and we are given the joint probability distribution, we need to calculate \[
\Cov{X,Y} = \sum_{x,y} ( x - \E{X} )(y - \E{Y})p(x,y).
\] Covariance is measured in unit of \(X^2\times\)unit of \(Y^2\). This can be inconvenient and makes it hard to compare covariances of different pairs of variables. A more convenient metric is the correlation, which is defined by \[
\Cor{X,Y}= \frac{ \Cov{X,Y} }{ \sd{X} \sd{Y} }.
\] Correlation, \(\Cor{X,Y}\), is unites and takes values between 0 and 1.
In the case of joint continuous distribution it is convenient to use the covariance matrix \(\Sigma\) which is defined as \[
\Sigma = \begin{bmatrix}
\Var{X} & \Cov{X,Y} \\
\Cov{X,Y} & \Var{Y}
\end{bmatrix}.
\] If \(X\) and \(Y\) are independent, then \(\Cov{X,Y} = 0\) and \(\Sigma\) is diagonal. The correlation matrix is defined as \[
\rho = \begin{bmatrix}
1 & \Cor{X,Y} \\
\Cor{X,Y} & 1
\end{bmatrix}.
\] If \(X\) and \(Y\) have an exact linear relationship, then \(\Cor{X,Y} = 1\) and \(\Cov{X,Y}\) is the product of standard deviations. In matrix notations, the relation between the covariance matrix and correlation matrix is given by \[
\rho = \mathrm{diag}\left(\Sigma\right)^{-\dfrac{1}{2}} \Sigma\mathrm{diag}\left(\Sigma\right)^{-\dfrac{1}{2}},
\] where \(\sigma\) is a diagonal matrix with standard deviations on the diagonal.
5.2.2 Portfolios: Linear combinations
Calculating means and standard deviations of combination of random variables is central tool in probability. It is known as the portfolio problem. Let \(P\) be your portfolio, which comprises a mix of two assets \(X\) and \(Y\), typically stocks and bonds, \[
P = aX + bY,
\] where \(a\) and \(b\) are the portfolio weights, typically \(a+b=1\), as we are allocating our total capital. Imagine, that you have placed \(a\) dollars on the random outcome \(X\), and \(b\) dollars on \(Y\). The portfolio \(P\) measures your total weighted outcome.
Key portfolio rules: The expected value and variance follow the relations \[\begin{align*}
\E{aX + bY} = & a\E{X}+b\E{Y}\\
\Var{ aX + bY } = & a^2 \Var{X} + b^2 \Var{Y} + 2 ab \Cov{X,Y },
\end{align*}\] with covariance defined by \[
\Cov{X,Y} = \E{ ( X- \E{X} )(Y- \E{Y})}.
\] Expectation and variance help us to understand the long-run behavior. When we make long-term decisions, we need to use the expectations to avoid biases.
The covariance is related to the correlation by \(\Cov{X,Y} = \text{Corr}(X, Y) \cdot \sqrt{\text{Var}{X} \cdot \text{Var}{Y}}\).
Example 5.2 (Tortoise and Hare) Tortoise and Hare who are selling cars. Say \(X\) is the number of cars sold and probability distributions, means and variances is given by the following table
What do these tell us about the long run behavior?
Tortoise and Hare have the same expected number of cars sold.
Tortoise is more predictable than Hare. He has a smaller variance.
The standard deviations \(\sqrt{\Var{X}}\) are \(0.5\) and \(1.5\), respectively. Given two equal means, you always want to pick the lower variance. If we are to invest into one of those, we prefer Tortoise.
Often, it is easier to communicate uncertainties in a form of odds. In terms of betting odds of \(1:1\) gives \(P = \frac{1}{2}\), odds on \(2:1\) (I give \(2\) for each \(1\) you bet) is \(P = \frac{1}{3}\).
Remember, odds, \(O(A)\), is the ratio of the probability of not happening over happening, \[
O(A) = (1 - P(A)) / P(A),
\] equivalently, \[
P(A) = \frac{1}{1 + O(A)}.
\]
The odds of patriot winning sequence in then 1 to 199
(1-0.005)/0.005
199
5.3 Bellman Principle of Optimality
Example 5.3 (Secretary Problem) The Secretary Problem, also known as the “marriage problem” or “sultan’s dowry problem,” is a classic problem in decision theory and probability theory. The scenario involves making a decision on selecting the best option from a sequence of candidates or options. The problem is often framed as hiring a secretary, but it can be applied to various situations such as choosing a house, a spouse, or any other scenario where you sequentially evaluate options and must make a decision.
In this problem, you receive \(T\) offers and must either accept (or reject) the offer “on the spot”. You cannot return to a previous offer once you have moved on to the next one. Offers are in random order and can be ranked against those previously seen. The aim is to maximize the probability of choosing the offer with the greatest rank. There is an optimal \(r\) (\(1 \le r < T\)) to be determined such that where we examine and reject the first \(r\) offers. Then of the remaining \(T - r\) offers we choose the first one that is best seen to date.
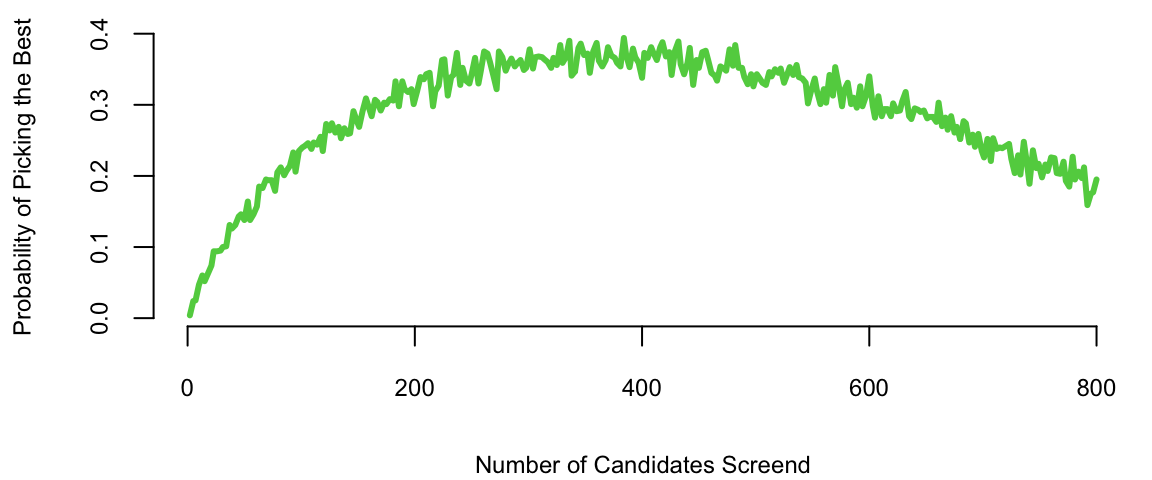
A decision strategy involves setting a threshold such that the first candidate above this threshold is hired, and all candidates below the threshold are rejected. The optimal strategy, known as the “37% rule,” suggests that one should reject the first \(r=T/e\) candidates and then select the first candidate who is better than all those seen so far.
The reasoning behind the 37% rule is based on the idea of balancing exploration and exploitation. By rejecting the first \(T/e\) candidates, you gain a sense of the quality of the candidates but avoid committing too early. After that point, you select the first candidate who is better than the best among the initial \(r\) candidates.
It’s important to note that the 37% rule provides a probabilistic guarantee of selecting the best candidate with a probability close to 1/e (approximately 37%) as \(T\) becomes large.
To solve the secretary problem, we will use the principle of optimality due to Richard Bellman. The principle states that an optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision. In other words, the policy is optimal from the first decision onwards.
The solution to the secretary problem can be found via dynamic programming. Given an agent with utility function \(u(x,d,t)\), with current state \(x_t\), and decision \(d_t\). The law of motion of \(x_t\) is given by \(x_{t+1} = p(x_t,d_t,t)\). Bellman principle of optimality states that the optimal policy is given by the following recursion \[
V(x_t,t) = \max_{d_t} \left \{ u(x_t,d_t,t) + \beta \mathbb{E} \left [ V(x_{t+1},t+1) \right ] \right \}
\] where \(\beta\) is the discount factor. The optimal policy is given by \[
d_t^* = \arg \max_{d_t} \left \{ u(x_t,d_t,t) + \beta \mathbb{E} \left [ V(x_{t+1},t+1) \right ] \right \}.
\]
Now, back to the secretary problem. Let \(y^t\) denote the history of observations up to time \(t\). State \(x_t=1\) if the \(t\)th candidate is the best seen so far and \(x_t=0\) otherwise. The decision \(d_t=1\) if the \(t\)th candidate is hired and \(d_t=0\) otherwise. The utility function is given by \(u(x_t,d_t,t) = x_t d_t\). The law of motion is given by \(x_{t+1} = \max \{ x_t, x_{t+1} \}\). The Bellman equation is given by \[
P(\text{best of T}\mid x_t=1) = \dfrac{P(\text{best of T})}{x_t=1} = \dfrac{1/T}{1/t} = \dfrac{t}{T}.
\] The \(t\)th offer is the best seen so far places no restriction on the relative ranks of the first \(t-1\) offers. Therefore, \[
p(x_t=1,y^{t-1}) = p(x_t=1)p(y^{t-1})
\] by the independence assumption. Hence, we have \[
p(x_t=1 \mid y^{t-1}) = p(x_t=1) = \dfrac{1}{t}.
\]
Let \(p(x=0,t-1)\) be the probability under the optimal strategy. Now we have to select the best candidate, given we have seen \(t-1\) offers so far and the last one was not the best or worse. The probability satisfies the Bellman equation \[
p(x=0,t-1) = \frac{t-1}{t} p(x=0,t) + \frac{1}{t}\max\left(t/T, p(x=0,t)\right).
\] This leads to \[
p(x=0,t-1) = \frac{t-1}{T} \sum_{\tau=t-1}^{T-1}\dfrac{1}{\tau}.
\]
Remember, the strategy is to reject the first \(r\) candidates and then select the first The probability of selecting the best candidate is given by \[
P(\text{success}) = \dfrac{1}{T}\sum_{a=r+1}^T \dfrac{r}{a} \approx \dfrac{1}{T}\int_{r}^{T}\dfrac{r}{a} = \dfrac{r}{T} \log \left ( \dfrac{T}{r} \right ).
\] We optimize over \(r\) by setting the derivative \[
\frac{\log \left(\frac{T}{r}\right)}{T}-\frac{1}{T}
\] to zero, to find the optimal \(r=T/e\).
If we plug in \(r=T/e\) back to the probability of success, we get \[
P(\text{success}) \approx \dfrac{1}{e} \log \left ( e \right ) = \dfrac{1}{e}.
\]
5.4 Monte Carlo Simulations
Simulations are a powerful tool for making decisions when we deal with a complex system, which is difficult or impossible to analyze mathematically. They are used in many fields, including finance, economics, and engineering. They can also be used to test hypotheses about how a system works and to generate data for statistical analysis.
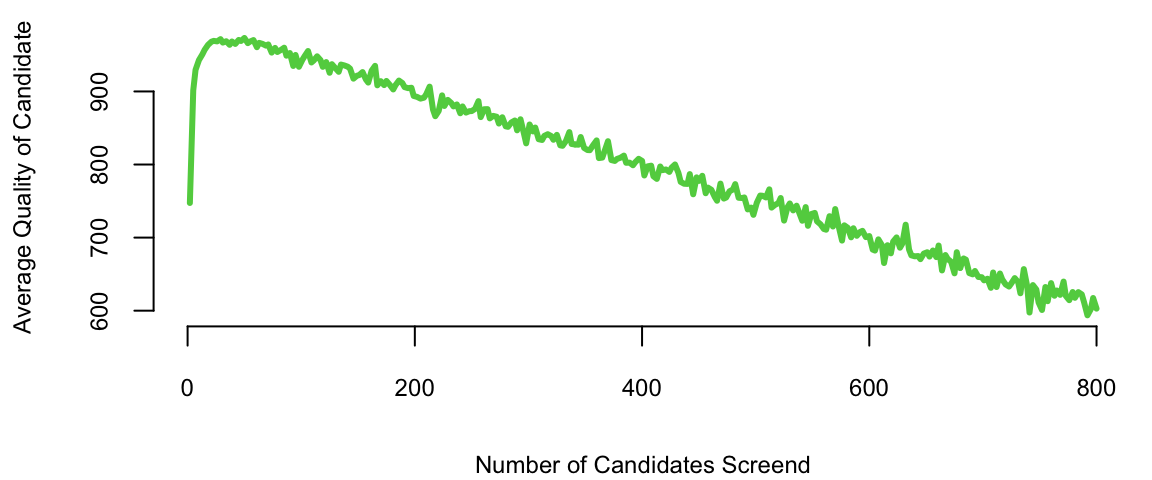
We start by showing how the secretary problem can be analyses using simulations rather than alanytical derivations provided above.
plot(d$rules, d$cnt/d$nmc, type='l', col=3, lwd=3, xlab="Number of Candidates Screend", ylab="Probability of Picking the Best")
Code
plot(d$rules, d$quality/1000, type='l', col=3, lwd=3, xlab="Number of Candidates Screend", ylab="Average Quality of Candidate")
Example 5.4 (Yahoo Stock Price Simulation) Investing in volatile stocks can be very risky. The Internet stocks during the late 1990’s were notorious for their volatility. For example, the leading Internet stock Yahoo! started 1999 at $62,rose to $122, then fell back to $55 in August, only to end the year at $216. Even more remarkable is the fact that byJanuary 2000, Yahoo! has risen more than 100-fold from its offering price of $1.32 on April 15, 1996. In comparison, theNasdaq 100, a benchmark market index, was up about 5-fold during the same period.
Stock prices fluctuate somewhat randomly. Maurice Kendall, in his seminal 1953 paper on the random walk nature of stock and commodity prices, observed that “The series looks like a wandering one, almost as if once a week the Demon of Chance drew a random number from a symmetrical population of fixed dispersion and added to it the current price to determine next week’s price (p. 87).” While a pure random walk model for Yahoo!’s stock price is in fact not reasonable since its price cannot fall below zero, an alternative model tha appears to provide reasonable results assumes that the logarithms o price changes, or returns, follow a random walk. This alternative mode is the basis for the results in this article.
To evaluate a stock investment, we take the initial price as \(S(0)\) and then we need to determine what the stock price might be in year \(T\), namely \(S(T)\). Our approach draws from the Black-Scholes Model for valuing stock options. Technically, the Black-Scholes Model assumes that \(S(T)\) is determined by the solution to a stochastic differential equation (see sidebar). The important consequence of the model for predicting future prices is that \(\log(S(T)/S(0))\) has a normal distribution with mean \((\mu-\frac{1}{2} \sigma^2)T\) and variance \(\sigma^2 T\) which is equivalent to saying that the ratio \(S(T)/S(0)\) has a log-normal distribution. It is interesting that although the Black-Scholes result is a standard tool for valuing options in finance the log-normal predictive distribution that follows from its assumptions is not commonly studied. In order to forecast \(S(T)\) we need to estimate the unknowns \(\mu\) and \(\sigma\) (recall \(S(0)\) is known). The unknown parameters \(\mu\) and \(\sigma\) can be interpreted as the instantaneous expected rate of return and the volatility, respectively. The mean parameter \(\mu\) is known as the expected rate of return because the expected value of \(S(T)\) is \(S(0)e^{\mu T}\). There are a number of ways of estimating the unknown parameters. One approach is to use an equilibrium model for returns, such as the Capital Asset Pricing Model or CAPM.
Rather than estimate \(\mu\) directly, the CAPM estimates the difference between \(\mu\) and the risk-free rate \(r_f\). This quantity \(\mu-r_f\) is known as the expected excess return (excess relative to a risk-free investment). The CAPM relates the expected excess return of a stock to that of an underlying benchmark, typically a broad-based market index. Let \(\mu_M\) and \(\sigma_M\) denote the return and volatility on the market index. The implication of CAPM is that there is a linear relationship between the expected excess return of a stock, \(\mu-r_f\), and the excess return of the market, \(\mu_M-r_f\). \[
\text{Excess \; Return}_{\text{Stock}} = \beta \; \text{Excess \;
Return}_{\text{Market}}
\]\[
\mu-r_f = \beta(\mu_M - r_f )
\] Put simply, the expected excess return of a stock is \(\beta\) times the excess expected return of the market. Beta (\(\beta\)) is a measure of a stock’s risk in relation to the market. A beta of 1.3 implies that the excess return on the stock is expected to move up or down 30% more than the market. A beta bigger than one implies the stock is riskier than the market and goes up (and down) faster than the market goes up (and down). A beta less than one implies the stock is less risky than the market.
Using the CAPM, the expected return of the stock can now be defined as the risk free interest rate plus beta times the expected excess return of the market, \[
\mu = \text{Expected \; Return}_{\text{Stock}} = r_f+\beta (\mu_M-r_f)
\] Beta is typically estimated from a regression of the individual stock’s returns on those of the market. The other parameters are typically measured as the historical average return on the market \(\mu_M\) and the yield on Treasury Bills \(r_f\). Together these form an estimate of \(\mu\). The volatility parameter \(\sigma\) is estimated by the standard deviation of historical returns.
Our qualitative discussion implicitly took the year as the unit of time. For our example, we make one minor change and consider daily returns so that \(\mu\) and \(\sigma\) are interpreted as a daily rate of return and daily volatility (or standard deviation). We use an annual risk-free rate of 5%; this makes a daily risk-free rate of .019%, \(r_f = 0.00019\), assuming there are 252 trading days in a year. A simple historical average is used to estimate the market return (\(\mu_M\)) for the Nasdaq 100. The average annual return is about 23%, with corresponding daily mean \(\mu_M = 0.00083\). A regression using daily returns from 1996-2000 leads to an estimate of \(\beta = 1.38\). Combining these (pieces) leads to an estimated expected return of Yahoo!, \(\mu_{Yahoo} = 0.00019+1.38(0.00083-0.00019) = 0.00107\) on a daily basis. Note that the CAPM model estimates a future return that is much lower than the observed rate over the last three-plus years of .42% per day or 289% per year.
To measure the riskiness of Yahoo! notice that the daily historical volatility is 5%, i.e. \(\sigma = 0.05\). On an annual basis this implies a volatility of \(\sigma \sqrt{T} = 0.05 \sqrt{252} = 0.79\), that is 79%. For comparison, the benchmark Nasdaq 100 has historical daily volatility 1.9% and an annual historical volatility of 30%. The estimates of all the parameters are recorded in Table 5.1.
Table 5.1: Key Parameter Estimates Based on Daily Returns 1996–2000
Asset
Expected return
Volatility
Regression coefft (s.e.)
Yahoo!
\(\mu = 0.00107\)
\(\sigma = 0.050\)
\(\beta = 1.38 (.07)\)
Nasdaq 100
\(\mu_M = 0.00083\)
\(\sigma_M = 0.019\)
1
Treasury Bills
\(r_f = 0.00019\)
–
–
5.5 Expected Utility
Let \(P,Q\) be two possible risky gambles or probability bets. An agents preferences can then be specified as an ordering on probability bets where we write \(P\)\(Q\) as \(P \succeq Q\) and indifference as \(P \sim Q\). A compound or mixture bet is defined by the probability assignment \(p P + (1 - p ) Q\) for a prospected weight \(0 \leq p \leq 1\).
Ramsey-de Finetti-Savage show that if an agents’ preferences satisfy a number of plausible axioms – completeness, transitivity, continuity and independence – then they can be represented by the expectation of a utility function. The theory is a normative one and not necessarily descriptive. It suggests how a rational agent should formulate beliefs and preferences and not how they actually behave.
This representation of preferences in terms of expected utility \(U(P)\) of a risky gamble is then equivalent to \[
P \succeq Q \; \; \iff \; \; U (P) \geq U (Q )
\] Therefore, the higher the value taken by the utility function the more the gamble is preferred. Specifically, the axioms lead to existence of expected utility and uniqueness of probability.
The two key facts then are uniqueness of probability and existence of expected utility. Formally,
If \(P \succeq R \succeq Q\) and \(p P + (1 - p ) Q \sim R\) then \(p\) is unique.
There exists an expected utility \(U(\cdot )\) such that \(P \succeq Q \; \; \iff \; \; U (P) \geq U (Q)\). Furthermore \[
U \left (p P + (1 - p ) Q \right ) = pU (P) +(1 - p ) U(Q)
\] for any \(P, Q\) and \(0 \leq p \leq 1\).
This implies that \(U\) is additive and it is also unique up to affine transformation.
The usual situation can be described as follows. Let \(\Omega\) be a finite set of possible outcomes with \(\Omega = \{ \omega_1 , \ldots , \omega_n \}\). Let \(P_i\) be the probability that assigns one to outcome \(\omega_i\) and zero otherwise and let \(P = ( p_1 , \ldots , p_n )\) assign probability \(p_i\) to outcome \(\omega_i\). Then we can write the expected utility, \(U(P)\), of the gamble \(P\) as \(U(P) = \sum_{i=1}^n p_i U( P_i )\). That is, the utility of \(P\) is the expected value of a random variable \(X\) that takes the value \(u(P_i)\) if the outcome is \(\omega_i\). Therefore, we can write \(U(P) = \mathbb{E}_P \left ( U( X ) \right)\).
This leads us to the notion of risk aversion and a categorization of agents according to their risk tolerance: the agent is said to be
Risk Averse if \(\mathbb{E}_P \left ( u(X) \right ) \leq u \left ( \mathbb{E}_P ( X) \right )\)
Risk Neutral if \(\mathbb{E}_P \left ( u(X) \right ) \leq u \left ( \mathbb{E}_P ( X) \right )\)
Risk Seeking if \(\mathbb{E}_P \left ( u(X) \right ) \geq u \left ( \mathbb{E}_P ( X) \right )\)
under the assumption that these hold for all probabilities and random variables. Risk aversion is equivalent to the agent having concave utility and risk seeking convex.
Proof: If \(w\) is not unique then \(\exists w_1\) such that \(w_1 P + (1 - w_1 ) Q \sim R\). Without loss of generality assume that \(w_1 < w\) and so \(0 < w - w_1 < 1 - W1\). However, we can write the bet \(Q\) as \[
Q = \left ( \frac{w-w_1}{1-w_1} \right ) Q + \left ( \frac{1-w}{1-w_1} \right ) Q
\] By transitivity, as \(P \succeq Q\) we have \[
\left ( \frac{w-w_1}{1-w_1} \right ) P + \left ( \frac{1-w}{1-w_1} \right ) Q \succeq Q
\] However \[
w P + ( 1 - w) Q = w_1 P + (1 - w_1 ) \left ( \left ( \frac{w-w_1}{1-w_1} \right ) P + \left ( \frac{1-w}{1-w_1} \right ) Q
\right )
\] implying by transitivity that \[
w P + (1 - w ) Q \succeq w_1 P + (1 - w_1 ) Q
\] which is a contradiction.
This can be used together with the axioms to then prove the existence and uniqueness of a utility function,
Theorem 5.1 If \(V\) is any other function satisfying these results then \(V\) is an affine function of \(U\).
Proof. If \(\forall P , Q\) we have \(P \sim Q\), then define \(u(P) \equiv 0\). Hence suppose that there exists \(S \succ T\). Define \(U(S) =1\) and \(U(T)=0\). For any \(P \in \mathcal{P}\) there are five possibilities: \(P \succ T\) or \(P \sim S\) or \(S \succ P \succ T\) or \(P \sim T\) or \(T \succ P\).
In the first case define \(1/U(P)\) to be the unique \(p\) (see previous theorem) defined by \(p P + ( 1 -p )T \sim S\). In the second case, define \(U(P) =1\). In the third, there exists a unique \(q\) with \(q S + ( 1 -q )T \sim P\) and then define \(U(P)=q\). In the fourth case, define \(U(P)=0\) and finally when \(T \succ P\) there exists a unique \(r\) with \(r S + ( 1-r )P \sim T\) and then we define \(U(P) = - r / (1 - r)\).
Then check that \(U(P)\) satisfies the conditions. See Savage (1954), Ramsey (1927) and de Finetti (1931)
Other interesting extensions: how do people come to a consensus (DeGroot, 1974, Morris, 1994, 1996). Ramsey (1926) observation that if someone is willing to offer you a bet then that’s conditioning information for you. All probabilities are conditional probabilities.
Example 5.5 (Kelly Criterion) Suppose you have $1000 to invest. With probability \(0.55\) you will win whatever you wager and with probability \(0.45\) you lose whatever you wager. What’s the proportion of capital that leads to the fastest compounded growth rate?
Quoting Kelly (1956), the exponential rate of growth, \(G\), of a gambler’s capital is \[
G = \lim_{N\to \infty} \frac{1}{N} \log_2 \frac{V_N}{V_0}
\] for initial capital \(V_0\) and capital after \(N\) bets \(V_N\).
Under the assumption that a gambler bets a fraction of his capital, \(\omega\), each time, we use \[
V_N = (1+\omega)^W (1-\omega)^L V_0
\] where \(W\) and \(L\) are the number of wins and losses in \(N\) bets. We get \[
G = p \log_2(1+\omega)+ q \log_2(1-\omega)
\] in which the limit(s) of \(\frac{W}{N}\) and \(\frac{L}{N}\) are the probabilities \(p\) and \(q\), respectively.
This also comes about by considering the sequence of i.i.d. bets with \[
p ( X_t = 1 ) = p \; \; \text{ and} \; \; p ( X_t = -1 ) = q=1-p
\] We want to find an optimal allocation \(\omega^*\) that maximizes the expected long-run growth rate: \[\begin{align*}
\max_\omega \mathbb{E} \left ( \ln ( 1 + \omega W_T ) \right )
& = p \ln ( 1 + \omega ) + (1 -p) \ln (1 - \omega ) \\
& \leq p \ln p + q \ln q + \ln 2 \; \text{ and} \; \omega^\star = p - q
\end{align*}\]
The solution is \(w^* = 0.55 - 0.45 = 0.1\).
Both approaches give the same optimization problem, which, when solved, give the optimal fraction rate \(\omega^* = p-q\), thus, with \(p=0.55\), the optimal allocation is 10% of capital.
We can generalize the rule to the case of asymmetric payouts \((a,b)\). Then the expected utility function is \[
p \ln ( 1 + b \omega ) + (1 -p) \ln (1 - a \omega )
\] The optimal solution is \[
\omega^\star = \frac{bp - a q}{ab}
\]
If \(a=b=1\) this reduces to the pure Kelly criterion.
A common case occurs when \(a=1\) and market odds \(b=O\). The rule becomes \[
\omega^* = \frac{p \cdot O -q }{O}.
\]
Let’s consider another scenario. You have two possible market opportunities: one where it offers you \(4/1\) when you have personal odds of \(3/1\) and a second one when it offers you \(12/1\) while you think the odds are \(9/1\).
In expected return these two scenarios are identical both offering a 33% gain. In terms of maximizing long-run growth, however, they are not identical.
Table 5.2 shows the Kelly criteria advises an allocation that is twice as much capital to the lower odds proposition: \(1/16\) weight versus \(1/40\).
Table 5.2: Kelly rule
Market
You
\(p\)
\(\omega^\star\)
\(4/1\)
\(3/1\)
\(1/4\)
\(1/16\)
\(12/1\)
\(9/1\)
\(1/10\)
\(1/40\)
The optimal allocation \(\omega^\star = ( p O - q ) / O\) is \[
\frac{ (1/4) \times 4 - (3/4) }{4} = \frac{1}{16} \; \text{ and} \;
\frac{ (1/10) \times 12 - (9/10) }{12} = \frac{1}{40}.
\]
Power utility and log-utilities allow to model constant relative risk aversion (CRRA). The main advantage that the optimal rule is unaffected by wealth effects. The CRRA utility of wealth takes the form \[
U_\gamma (W) = \frac{ W^{1-\gamma} -1 }{1-\gamma}
\]
The special case \(U(W) = \log (W )\) for \(\gamma = 1\).
This leads to a myopic Kelly criterion rule.
5.6 Unintuitive Nature of Decision Making
Example 5.6 (Saint Petersburg Paradox) The Saint Petersburg paradox is a concept in probability and decision theory that was first introduced by Daniel Bernoulli in 1738. It revolves around the idea of how individuals value risky propositions and how those valuations may not align with classical expected utility theory.
The paradox is named after the city of Saint Petersburg, where the problem was formulated. Here’s a simplified version of the paradox:
Imagine a gambling game where a fair coin is flipped repeatedly until it lands on heads. The payoff for the game is \(2^n\), where n is the number of tosses needed for the coin to land on heads. The expected value of this game, calculated by multiplying each possible payoff by its probability and summing the results, is infinite:
This means that, in theory, a rational person should be willing to pay any finite amount to play this game, as the expected value is infinite. However, in reality, most people would be unwilling to pay a large amount to play such a game.
The paradox arises because traditional expected utility theory assumes that individuals make decisions based on maximizing their expected gain. Bernoulli argued that people do not maximize expected monetary value but rather expected utility, where utility is a subjective measure of satisfaction or happiness. He proposed that individuals exhibit diminishing marginal utility for wealth, meaning that the additional satisfaction gained from an extra unit of wealth decreases as total wealth increases.
In the case of the Saint Petersburg paradox, although the expected monetary value is infinite, the utility gained from each additional dollar diminishes rapidly, leading to a reluctance to pay large amounts to play the game.
In modern decision theory and economics, concepts like diminishing marginal utility and expected utility are fundamental in understanding how individuals make choices under uncertainty and risk. The Saint Petersburg paradox highlights the limitations of relying solely on expected monetary value in explaining human behavior in such situations.
One common approach is to consider aspects of potential players, such as their possible risk aversion, available funds, etc., through a utility function \(U(x)\). Applying a utility function in this situation means changing our focus to the quantity \[
E[U(X)] = \sum^\infty_{k=1} 2^{-k} U(2^k).
\]
Some examples of utility functions are,
\(U(x) = V_0 (1-x^{-\alpha})\), \(\alpha > 0\), which gives an expected utility of \(V_0 \left(1-\frac{1}{2^{\alpha+1}-1}\right)\)
Log utility, \(U(x) = \log(x)\), with expected value \(2 \log(2)\).
Notice that after obtaining an expected utility value, you’ll have to find the corresponding reward/dollar amount.
Example 5.7 (Ellsberg Paradox: Ambiguity Aversion) The Ellsberg paradox is a thought experiment that was first proposed by Daniel Ellsberg in 1961. It is a classic example of a situation where individuals exhibit ambiguity aversion, meaning that they prefer known risks over unknown risks. The paradox highlights the importance of considering ambiguity when making decisions under uncertainty.
Example 5.8 (Allais Paradox: Independence Axiom) The Allais paradox is a choice problem designed by Maurice Allais to show an inconsistency of actual observed choices with the predictions of expected utility theory. The paradox is that the choices made in the second problem seem irrational, although they can be explained by the fact that the independence axiom of expected utility theory is violated.
We run two experiments. In each experiment a participant has to make a choice between two gambles.
Experiment 1
Gamble \({\cal G}_1\)
Gamble \({\cal G}_2\)
Win
Chance
Win
Chance
$25m
0
$25m
0.1
$5m
1
$5m
0.89
$0m
0
$0m
0.01
Experiment 2
Gamble \({\cal G}_2\)
Gamble \({\cal G}_4\)
Win
Chance
Win
Chance
$25
0
$25m
0.1
$5
0.11
$5m
0
$0m
0.89
$0m
0.9
The difference in expected gains is identical in two experiments
However, typically a person prefers \({\cal G}_1\) to \({\cal G}_2\) and \({\cal G}_4\) to \({\cal G}_3\), we can conclude that the expected utilities of the preferred is greater than the expected utilities of the second choices. The fact is that if \({\cal G}_1 \geq {\cal G}_2\) then \({\cal G}_3 \geq {\cal G}_4\) and vice-versa.
Assuming the subjective probabilities \(P = ( p_1 , p_2 , p_3)\). The expected utility \(E ( U | P )\) is \(u ( 0 ) = 0\) and for the high prize set \(u ( \$ 25 \; \text{million} ) = 1\). Which leaves one free parameter \(u = u ( \$ 5 \; \text{million} )\).
Hence to compare gambles with probabilities \(P\) and \(Q\) we look at the difference \[
E ( u | P ) - E ( u | Q ) = ( p_2 - q_2 ) u + ( p_3 - q_3 )
\]
For comparing \({\cal G}_1\) and \({\cal G}_2\) we get \[\begin{align*}
E ( u | {\cal G}_1 ) - E ( u | {\cal G}_2 ) &= 0.11 u - 0.1 \\
E ( u | {\cal G}_3 ) - E ( u | {\cal G}_4 ) &= 0.11 u - 0.1
\end{align*}\] The order is the same, given your \(u\). If your utility satisfies \(u < 0.1/0.11 = 0.909\) you take the “riskier” gamble.
Example 5.9 (Monty Hall Problem) Another example of a situation when calculating probabilities is counterintuitive. The Monte Hall problems was named after the host of the long-running TV show Let’s make a Deal. The original solution was proposed by Marilyn vos Savant, who had a column with the correct answer that many Mathematicians thought was wrong!
The game set-up is as follows. A contestant is given the choice of 3 doors. There is a prize (a car, say) behind one of the doors and something worthless behind the other two doors: two goats. The game is as follows:
You pick a door.
Monty then opens one of the other two doors, revealing a goat. He can’t open your door or show you a car
You have the choice of switching doors.
The question is, is it advantageous to switch? The answer is yes. The probability of winning if you switch is 2/3 and if you don’t switch is 1/3.
Conditional probabilities allow us to answer this question. Assume you pick door 2 (event \(A\)) at random, given that the host opened Door 3 and showed a goat (event B), we need to calculate \(P(A\mid B)\). The prior probability that the car is behind Door 2 is \(P(A) = 1/3\) and \(P(B\mid A) = 1\), if the car is behind Door 2, the host has no choice but to open Door 3. The Bayes rule then gives us \[
P(A\mid B) = \frac{P(B\mid A)P(A)}{P(B)} = \frac{1/3}{1/2} = \frac{2}{3}.
\] The overall probability of the host opening Door 3 \[
P(B) = (1/3 \times 1/2) + (1/3 \times 1) = 1/6 + 1/3 = 1/2.
\]
The posterior probability that the car is behind Door 2 after the host opens Door 3 is 2/3. It is to your advantage to switch doors.
Example 5.10 (Winner’s Curse) One of the interesting facts about expectation is that when you are in a competitive auctioning game then you shouldn’t value things based on pure expected value. You should take into consideration the event that you win \(W\). Really you should be calculating \(E(X\mid W)\) rather than \(E(X)\).
The winner’s curse: given that you win, you should feel regret: \(E(X\mid W) < E(X)\).
A good example is claiming racehorse whose value is uncertain.
Value
Outcome
0
horse never wins
50,000
horse improves
Simple expected value tells you \[
E(X) = \frac{1}{2} \cdot 0 + \frac{1}{2} \cdot 50,000 = \$25,000.
\] In a $20,000 claiming race (you can buy the horse for this fixed fee ahead of time from the owner) it looks like a simple decision to claim the horse.
Its not so simple! We need to calculate a conditional expectation. What’s \(E( X\mid W )\), given you win event (\(W\))? This is the expected value of the horse given that you win that is relevant to assessing your bid. In most situations \(E(X\mid W) < 20,000\).
Another related feature is this problem is . The owner or trainer of the horse maybe know something that you don’t know. There’s a reason why they are entering the horse into a claiming race in the first place.
Winner’s curse implies that immediately after you have win, you should feel a little regret, as the object is less valuable to you after you have won! Or put another way, in an auction nobody else in the room is willing to offer more than you at that time.
Example 5.11 (The Hat Problem) There are \(N\) guys in a forward facing line. Each guy is wearing a blue or red hat. Everyone can see all the hats in front of him, but cannot see his own hat. The hats can be in any combination of red and blue, from all red to all blue and every combination in between. The first guy doesn’t know his own hat. There is a rule that all can agree to follow such that the first guy makes a choice (“My hat is …”) and everyone after that, including the last guy, will get their color right with probability \(1\).
You have a \(100\)% chance of saving all but the last prisoner, and a \(50\)% chance of saving that one. Here’s the strategy the prisoners have agreed on. The last prisoner counts the number of blue hats worn; if the number is even, the last prisoner yells “blue”, if odd, yells “red”. If the \(99\)th prisoner hears “blue”, but counts an odd number of blue hats, then his hat must be blue so that the total number of blue hats is even. If he counts an even number of blue hats, then his hat must be red. If the last prisoner yells red, then 99 knows that there are an odd number of blue hats. So 99 counts the number of blue hats he can see. Again, if they are even, his hat is blue, if odd, his hat is red. The 99th prisoner then yells out the color of his hat and is spared. The next prisoner now knows whether the remaining number of blue hats, including his own, is odd or even, by taking into account whether 99 had a blue hat or not. Then by counting the number of blue hats he sees, he knows the color of his hat. So he yells out the color of his hat and is spared. This saves all but the last prisoner, and there is a \(50\)% chance that his hat is the color he shouted out.
One hundred prisoners are too many to work with. Suppose there are two. The last person can save the guy in front of him by shouting out the color of his hat. OK, how about if there are three? The third prisoner can see 0,1, or 2 blue hats. There seem to be three possibilities but only two choices of things to say. But, two of the possibilities have something in common namely the number of blue hats is even. So if the last prisoner yells “blue” then he can tell 1 and 2 that he sees an even number of blue hats. Then the second prisoner, by looking ahead and counting the number of blue hats, knows his must be blue if he sees one blue hat, and red if he sees no blue hats. The last prisoner agrees to yell “red” if the number of blue hats seen is odd. Then if 2 sees a blue hat on 1, his must be red, and if 1 has a red hat, his must be blue. By shouting out the color of his hat, 1 also knows his hat color. Two “blues” or two “reds” in a row mean he wears blue, while one blue and one red means he wears red. OK. This looks like this always works, because there are always only two possibilities as far as the number of blue hats worn they are either even or odd. So, check as in the three-person case that using this strategy (“blue” for an even number of blue hats “red” for an odd number) tells 99 the color of his hat, and then each prisoner in turn can learn the color of his hat by taking into account the parity of the number of blue hats he can see, the parity of the number of blue hats 100 saw and the number of prisoners behind him wearing blue hats.
Example 5.12 (Lemon’s Problem) The lemon problem is an interesting conditional probability puzzle and is a classic example of asymmetric information in economics. It was first proposed by George Akerlof in his 1970 paper “The Market for Lemons: Quality Uncertainty and the Market Mechanism.” The problem highlights the importance of information in markets and how it can lead to adverse selection, where the quality of goods or services is lower than expected.
Suppose that a dealer pays $20K for a car and wants to sell for $25K. Some cars on the market are Lemons. The dealer knows whether a car is a lemon. A lemon is only worth $5K. There is asymmetric information as the customer doesn’t know if the particular new car is a lemon. S/he estimates the probability of lemons on the road by using the observed frequency of lemons. We will consider two separate cases:
Let’s first suppose only 10% of cars are lemons.
We’ll then see what happens if 50% are lemons.
The question is how does the market clear (ie. at what price do car’s sell). Or put another way does the customer buy the car and if so what price is agreed on? This is very similar to winner’s curse: when computing an expected value what conditioning information should I be taking into account?
In the case where the customer thinks that \(p=0.10\) of the car’s are lemons, they are willing to pay \[
E (X)= \frac{9}{10} \cdot 25 + \frac{1}{10} \cdot 5 = \$ 23 K
\] This is greater than the initial $20 that the dealer paid. The car then sells at $23K \(<\) $25K.
Of course, the dealer is disappointed that there are lemons on the road as he is not achieving the full value – missing $2000. Therefore, they should try and persuade the customer its not a lemon by offering a warranty for example.
The more interesting case is when \(p=0.5\). The customer now values the car at \[
E (X) = \frac{1}{2} \cdot 25 + \frac{1}{2} \cdot 5 = \$ 15K
\] This is lower than the $20K – the reservation price that the dealer would have for a good car. Now what type of car and at what price do they sell?
The key point in asymmetric information is that the customer must condition on the fact that if the dealer still wants to sell the car, the customer must update his probability of the type of the car. We already know that if the car is not a lemon, the dealer won’t sell under his initial cost of $20K. So at $15K he is only willing to sell a lemon. But then if the customer computes a conditional expectation \(E( X \mid \mathrm{Lemon})\) – conditioning on new information that the car is a lemon \(L\) we het the valuation \[
E ( X \mid L ) = 1 \cdot 5 = \$ 5K
\] Therefore only lemons sell, at $ 5K, even if the dealer has a perfectly good car the customer is not willing to buy!
Again what should the dealer do? Try to raise the quality and decrease the frequency of lemons in the observable market. They type of modeling has all been used to understand credit markets and rationing in periods of loss of confidence.
Example 5.13 (Envelope Paradox) The envelope paradox is a thought experiment or puzzle related to decision-making under uncertainty. It is also known as the “exchange paradox” or the “two-envelope paradox.” The paradox highlights the importance of carefully considering the information available when making decisions under uncertainty and the potential pitfalls of making assumptions about unknown quantities.
A swami puts \(m\) dollars in one envelope and \(2 m\) in another. He hands on envelope to you and one to your opponent. The amounts are placed randomly and so there is a probability of \(\frac{1}{2}\) that you get either envelope.
You open your envelope and find \(x\) dollars. Let \(y\) be the amount in your opponent’s envelope. You know that \(y = \frac{1}{2} x\) or \(y = 2 x\). You are thinking about whether you should switch your opened envelope for the unopened envelope of your friend. It is tempting to do an expected value calculation as follows \[
E( y) = \frac{1}{2} \cdot \frac{1}{2} x + \frac{1}{2} \cdot 2 x = \frac{5}{4} x > x
\] Therefore, it looks as if you should switch no matter what value of \(x\) you see. A consequence of this, following the logic of backwards induction, that even if you didn’t open your envelope that you would want to switch!
Where’s the flaw in this argument? Use Bayes rule to update the probabilities of which envelope your opponent has! Assume \(p(m)\) of dollars to be placed in the envelope by the swami.
Such an assumption then allows us to calculate an odds ratio \[
\frac{ p \left ( y = \frac{1}{2} x | x \right ) }{ p \left ( y = 2 x | x \right ) }
\] concerning the likelihood of which envelope your opponent has.
Then, the expected value is given by \[
E(y) = p \left ( y = \frac{1}{2} x \; \vert \; x \right ) \cdot \frac{1}{2} x +
p \left ( y = 2 x | x \right ) \cdot 2 x
\] and the condition \(E( y) > x\) becomes a decision rule.
This is an open-ended problem, but it will not be very confusing if we well understand both the frequentist and bayesian approaches. Actually, this is a very good example to show how these two approaches are different and to check if we understand them correctly. There many conditions in this problem, so we cannot argue everything in this assignment; instead, we are going to focus on some interesting cases. First, assume we’re risk-neutral (although, we can simply change “money” with “utility” in this paradox, so it doesn’t matter). We will compare frequentist/bayesian, open/not open, and discrete/continuous. The finite, or bounded space, case will not be considered here since they are not very interesting.
Now, let \(X\) be the amount of money in my envelope, \(Y\) be the amount in my opponents. Let \(M_1\) be the amount of money in the first envelope and \(M_2(= 2 M_1)\) in the second one. \(X\) and \(Y\) are random variables while \(M_1\) and \(M_2\) are parameters.
If I DO NOT look in my envelope, in this case, even from a frequentist viewpoint, we can find a fallacy in this naive expectation reasoning \(E[trade] = 5X/4\) . First, the right answer from a frequentist view is, loosely, as follows. If we switch the envelope, we can obtain \(M_1\) (when \(X = M_1\)) or lose \(M_1\) (when \(X = M_2\)) with the same probability \(1/2\). Thus, the value of a trade is zero, so that trading matters not for my expected wealth.
Instead, naive reasoning is confusing the property of variable \(X\) and \(M_1\) . \(X\) is a random variable and \(M_1\) is a fixed parameter which is constant (again, from a frequentist viewpoint). By trading, we can obtain \(X\) (when \(X = M_1\)) or lose \(X/2\) (when \(X = 2 M_1\)) with the same probability \(1/2\). Here, the former \(X(= M_1)\) is different from the latter \(X(= 2 M_1 )\). Actually, the former \(X = M_1\) equals to the half of the latter \(X = 2 M_1 = M_2\). Thus, \(X \frac{1}{2} - \frac{X}{2} \frac{1}{2} = \frac{X}{4}\) is the wrong expected value of trading. On the other hand, from a bayesian view, since we have no information, we are indifferent to either trading or not.
The second scenario is if I DO look in my envelope. As the Christensen & Utts (1992) article said, the classical view cannot provide a completely reasonable resolution to this case. It is just ignoring the information revealed. Also, the arbitrary decision rule introduced at the end of the paper or the extension of it commented by Ross (1996) are not the results of reasoning from a classical approach. However, the bayesian approach provides a systematic way of finding an optimal decision rule using the given information. Most of the arguments in the Christensen & Utts (1992) paper are right, but there is one serious error in the article which is corrected in Bachman-Christensen-Utts (1996) and discussed in Brams & Kilgour (1995). The paper calculated the marginal density of \(X\) like below. \[\begin{align*}
p(X = x) &= p(M_1 = x)g(x) + p(M_2 = x)g(x/2) \\
&= \frac{1}{2} g(x) + \frac{1}{2} g(x/2)
\end{align*}\] where \(g(x)\) is the prior distribution of \(M_1\). However, integrating \(p(X = x)\) with respect to \(x\) from \(0\) to \(\infty\) gives \(3/2\) instead of \(1\). In fact, their calculation of \(p(X = x)\) can hold only when the prior distribution \(g(x)\) is discrete and \(p(X = x)\), \(g(m)\), \(g(m/2)\) represent the probabilities that \(X = x\), \(M_1 = m\), \(M_1 = m/2\), respectively.
For the correct calculation of the continuous \(X\) case, one needs to properly transform the distribution. That can be done by remembering to include the Jacobian term alongside the transformed PDF, or by working with the CDF of \(X\) instead. The latter forces one to properly consider the transform, and we proceed with that method.
Let \(G(x)\) be the CDF of the prior distribution of \(M_1\) corresponding to \(g(x)\). \[\begin{align*}
p(x < X \leq x+dx) &= p(M_1 = x)dG(x)+ p(M_2 = x)dG(x/2) \\
&= \frac{1}{2} \left( dG(x)+ dG(x/2) \right)
\end{align*}\] where \(g(x) = dG(x)/dx\). Now, the PDF of \(X\) is \[\begin{align*}
f_X(x) &= \frac{d}{dx} p(x < X \leq x + dx) \\
&= \frac{1}{2} \left(g(x) + \frac{1}{2} g(x/2) \right)
\end{align*}\] We have an additional \(1/2\) in the last term due to the chain rule, or the Jacobian in the change-in-variable formula. Therefore, the expected amount of a trade is \[\begin{align*}
E(Y\mid X = x) &= \frac{x}{2} p(M_2 = x\mid X = x) + 2 x \, p(M_1 = x\mid X = x) \\
&= \frac{x}{2} \frac{g(x)}{g(x) + g(x/2)/2} + 2 x \frac{g(x/2)/2}{g(x) + g(x/2)/2} \\
&= \frac{\frac{x}{2}g(x) + x g(x/2)}{g(x) + g(x/2)/2}
\end{align*}\]
Thus, for the continuous case, trading is advantageous whenever \(g(x/2) < 4g(x)\), instead of the decision rule for the discrete case \(g(x/2) < 2g(x)\).
Now, think about which prior will give you the same decision rule as the frequentist result. In the discrete case, \(g(x)\) such that \(g(x/2) = 2g(x)\), and in the continuous case \(g(x)\) such that \(g(x/2) = 4g(x)\). However, both do not look like useful, non-informative priors. Therefore, the frequentist approach does not always equal the Bayes approach with a non-informative prior. At the moment you start to treat \(x\) as a given number, and consider \(p(M_1 \mid X = x)\) (or \(p(Y \mid X = x)\)), you are thinking in a bayesian way, and need to understand the implications and assumptions in that context.
Leonard Jimmie Savage, an American statistician, developed a decision theory framework known as the “Savage axioms” or the “Sure-Thing Principle.” This framework is a set of axioms that describe how a rational decision-maker should behave in the face of uncertainty. These axioms provide a foundation for subjective expected utility theory.
The Savage axioms consist of three main principles:
Completeness Axiom:
This axiom assumes that a decision-maker can compare and rank all possible outcomes or acts in terms of preferences. In other words, for any two acts (or lotteries), the decision-maker can express a preference for one over the other, or consider them equally preferable.
Transitivity Axiom:
This axiom states that if a decision-maker prefers act A to act B and prefers act B to act C, then they must also prefer act A to act C. It ensures that the preferences are consistent and do not lead to cycles or contradictions.
Continuity Axiom (or Archimedean Axiom):
The continuity axiom introduces the concept of continuity in preferences. It implies that if a decision-maker prefers act A to act B, and B to C, then there exists some probability at which the decision-maker is indifferent between A and some lottery that combines B and C. This axiom helps to ensure that preferences are not too “discontinuous” or erratic.
Savage’s axioms provide a basis for the development of subjective expected utility theory. In this theory, decision-makers are assumed to assign subjective probabilities to different outcomes and evaluate acts based on the expected utility, which is a combination of the utility of outcomes and the subjective probabilities assigned to those outcomes.
Savage’s framework has been influential in shaping the understanding of decision-making under uncertainty. It allows for a more flexible approach to decision theory that accommodates subjective beliefs and preferences. However, it’s worth noting that different decision theorists may have alternative frameworks, and there are ongoing debates about the appropriateness of various assumptions in modeling decision-making.
5.7 Decision Trees
Decision trees can effectively model and visualize conditional probabilities. They provide a structured way to break down complex scenarios into smaller, more manageable steps, allowing for clear calculations and interpretations of conditional probabilities.
Each node in a decision tree, including thr root represents an event or condition. The branches represent the possible outcomes of that condition. Along each branch, you’ll often see a probability. This is the chance of that outcome happening, given the condition at the node. As you move down the tree, you’re looking at more specific conditions and their probabilities. The leaves of the tree show the final probabilities of various outcomes, considering all the conditions along the path to that leaf. Thus, the probabilities of the leaves need to sum to 1.
Example 5.14 (Medical Testing) A patient goes to see a doctor. The doctor performs a test which is 95% sensitive – that is 95 percent of people who are sick test positive and 99% specific – that is 99 percent of the healthy people test negative. The doctor also knows that only 1 percent of the people in the country are sick. Now the question is: if the patient tests positive, what are the chances the patient is sick? The intuitive answer is 99 percent, but the correct answer is 66 percent.
Formally, we have two binary variables, \(D=1\) that indicates you have a disease and \(T=1\) that indicates that you test positive for it. The estimates we know already are given by \(P(D) = 0.02\), \(P(T\mid D) = 0.95\), and \(P(\bar T \mid \bar D) = 0.99\). Here we used shortcut notations, instead of writing \(P(D=1)\) we used \(P(D)\) and instead of \(P(D=0)\) we wrote \(P(\bar D)\).
Sometimes it is more intuitive to describe probabilities using a tree rather than tables. The tree below shows the conditional distribution of \(D\) and \(T\).
flowchart LR
D[D] -->|0.02| D1(D=1)
D -->|0.98| D0(D=0)
D1 -->|0.95| D1T1(T=1)
D1 -->|0.05| D1T0(T=0)
D0 -->|0.01| D0T1(T=1)
D0 -->|0.99| D0T0(T=0)
Figure 5.1: Medical Diagnostics Decision Tree.
The result is not as intuitive as in the NBA example. Let’s think about this intuitively. Rather than relying on Bayes’s math to help us with this, let us consider another illustration. Imagine that the above story takes place in a small town, with \(1,000\) people. From the prior \(P(D)=0.02\), we know that 2 percent, or 20 people, are sick, and \(980\) are healthy. If we administer the test to everyone, the most probable result is that 19 of the 20 sick people test positive. Since the test has a 1 percent error rate, however, it is also probable that 9.8 of the healthy people test positive, we round it to 10.
Now if the doctor sends everyone who tests positive to the national hospital, there will be 10 healthy and 19 sick patients. If you meet one, even though you are armed with the information that the patient tested positive, there is only a 66 percent chance this person is sick.
Let’s extend the example and add the utility of the test and the utility of the treatment. Then the decision problem is to treat \(a_T\) or not to treat \(a_N\). The Q-function is the function of the state \(S \in \{D_0,D_1\}\) and the action \(A \in \{a_T,a_N\}\)
Utility of the test and the treatment.
A/S
\(a_T\)
\(a_N\)
\(D_0\)
90
100
\(D_1\)
90
0
Then expected utility of the treatment is 90 and no treatment is 2. A huge difference. Given our prior knowledge, we should not treat everyone.
0.02*90+0.98*90# treat
90
0.02*0+ (1-0.02)*100# do not treat
98
However, the expected utility will change when our probability of disease changes. Let’s say that we are in a country where the probability of disease is 0.1 or we performed a test and updated our prior probability of disease to some number \(p\). Then the expected utility of the treatment is \(E\left[U(a_T)\right]\) is 90 and no treatment is \[
E\left[U(a_N)\right] = 0\cdot p + 100 \cdot (1-p) = 100(1-p)
\] When we are unsure about the value of \(p\) we may want to explore how the optimal decision changes as we vary \(p\)
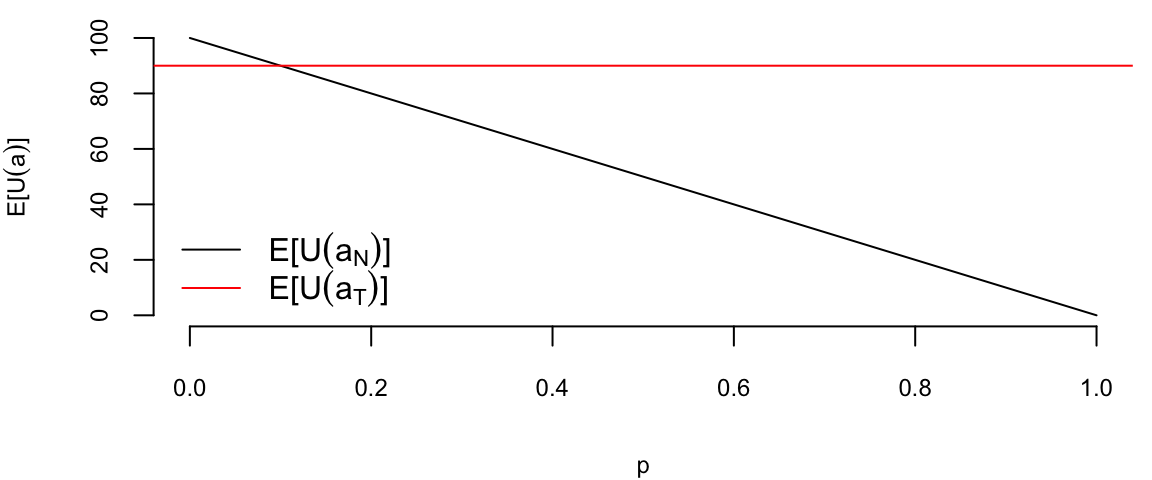
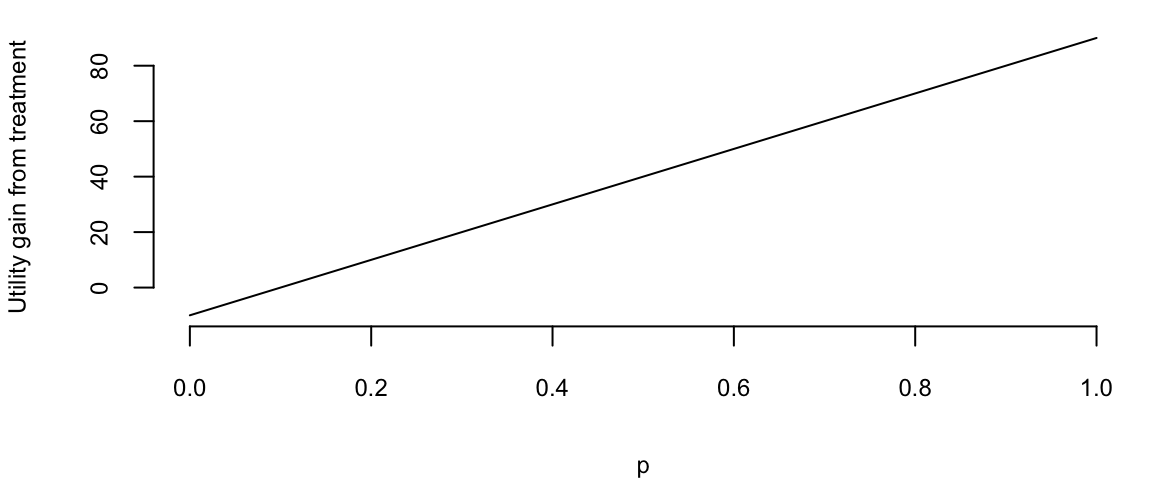
p =seq(0,1,0.01)plot(p, 100*(1-p), type ="l", xlab ="p", ylab =TeX("$E[U(a)]$"))abline(h=90, col="red")legend("bottomleft", legend =c(TeX("$E[U(a_N)]$"), TeX("$E[U(a_T)]$")), col =c("black", "red"), lty =1, bty='n')
Expected utility of the treatment and no treatment as a function of the prior probability of disease.
If our estimate at the crossover point, then we should be indifferent between treatment and no treatment, if on the left of the crossover point, we should treat, and if on the right, we should not treat. The crossover point is. \[
100(1-p) = 90, ~p = 0.1
\]
The gap of of \(0.9-100(1-p)\) is the expected gain from treatment.
plot(p, 90-100*(1-p), type ="l", xlab ="p", ylab =TeX("Utility gain from treatment"))
Not, let us calculate the value of test, e.g. the change in expected utility from the test. We will need to calculate the posterior probabilities
The best option is to treat now! Given the test our strategy is to treat if the test is positive and not treat if the test is negative. Let’s calculate the expected utility of this strategy.
# Expected utility of the strategypt*UT1 + pt0*UN0 %>%print()
100
100
The utility of out strategy of 100 is above of the strategy prior to testing (98), this difference of 2 is called the value of information.
Example 5.15 (Mudslide) I live in in a house that is at risk of being damaged by a mudslide. I can build a wall to protect it. The wall costs $10,000. If there is a mudslide, the wall will protect the house with probability \(0.95\). If there is no mudslide, the wall will not cause any damage. The prior probability of a mudslide is \(0.01\). If there is a mudslide and the wall does not protect the house, the damage will cost $100,0000. Should I build the wall?
Let’s formally solve this as follows:
Build a decision tree.
The tree will list the probabilities at each node. It will also list any costs there are you going down a particular branch.
Finally, it will list the expected cost of going down each branch, so we can see which one has the better risk/reward characteristics.
graph LR
R(( )) -->|Build: $40, $40.5| B(( ))
R -->|Don't Build: $0, $10| D(( ))
B -->|Slide: $0, $90| BS(( ))
B -->|No Slide: $0, $40| BN[40]
BS -->|Hold: $0, $40| BSH[40]
BS -->|Not Hold: $1000, $1040| BSN[1040]
D -->|Slide: $1000, $1000| DS[1000]
D -->|No Slide: $0, $0| DN[0]
The first dollar value is the cost of the edge, e.g. the cost of building the wall is $40,000. The second dollar value is the expected cost of going down that branch. For example, if you build the wall and there is a mudslide, the expected cost is $90,000. If you build the wall and there is no mudslide, the expected cost is $40,000. The expected cost of building the wall is $40,500. The expected cost of not building the wall is $10. The expected cost of building the wall is greater than the expected cost of not building the wall, so you should not build the wall. The dollar value at the leaf nodes is the expected cost of going down that branch. For example, if you build the wall and there is a mudslide and the wall does not hold, the expected cost is $1004000.
There’s also the possibility of a further test to see if the wall will hold. Let’s include the geological testing option. The test costs $3000 and has the following accuracies. \[
P( T \mid \mathrm{Slide} ) = 0.90 \; \; \mathrm{and } \; \; P( \mathrm{not~}T \mid
\mathrm{No \; Slide} ) = 0.85
\] If you choose the test, then should you build the wall?
Let’s use the Bayes rule. The initial prior probabilities are \[
P( Slide ) = 0.01 \; \; \mathrm{and} \; \; P ( \mathrm{No \; Slide} ) = 0.99
\]
\[\begin{align*}
P( T) & = P( T \mid \mathrm{Slide} ) P( \mathrm{Slide} ) +
P( T \mid \mathrm{No \; Slide} ) P( \mathrm{No \; Slide} ) \\
P(T)& = 0.90 \times 0.01 + 0.15 \times 0.99 = 0.1575
\end{align*}\] We’ll use this to find our optimal course of action.
The posterior probability given a positive test is \[\begin{align*}
P ( Slide \mid T ) & = \frac{ P ( T \mid Slide ) P ( Slide )}{P(T)} \\
& = \frac{ 0.90 \times 0.01}{ 0.1575} = 0.0571
\end{align*}\]
The posterior probability given a negative test is \[\begin{align*}
P \left ( \mathrm{Slide} \mid \mathrm{not~}T \right ) & = \frac{ P ( \mathrm{not~}T \mid \mathrm{Slide} ) P ( \mathrm{Slide} )}{P(\mathrm{not~}T)} \\
& = \frac{0.1 \times 0.01 }{0.8425} \\
& =0.001187
\end{align*}\]
Compare this to the initial base rate of a \(1\)% chance of having a mud slide.
Given that you build the wall without testing, what is the probability that you’ll lose everything? With the given situation, there is one path (or sequence of events and decisions) that leads to losing everything:
Given that you choose the test, what is the probability that you’ll lose everything? There are two paths that lead to losing everything:
There are three things that have to happen to lose everything. Test +ve (\(P=0.1575\)), Build, Slide (\(P= 0.0571\)), Doesn’t Hold (\(P=0.05\))
Now you lose everything if Test -ve (\(P=0.8425\)), Don’t Build, Slide given negative (\(P=0.001187\)).
The conditional probabilities for the first path \[
P ( \mathrm{first} \; \mathrm{path} ) = 0.1575 \times 0.0571 \times 0.05
= 0.00045
\]
For the second path \[
P ( \mathrm{second} \; \mathrm{path} ) = 0.8425 \times 0.001187 = 0.00101
\]
Hence putting it all together \[
P ( \mathrm{losing} \; \mathrm{everything} \mid \mathrm{testing} ) = 0.00045 + 0.00101 = 0.00146
\]
Putting these three cases together we can build a risk/reward table
Choice
Expected Cost
Risk
P
Don’t Build
$10,000
0.01
1 in 100
Build w/o testing
$40,500
0.0005
1 in 2000
Test
$10,760
0.00146
1 in 700
The expected cost with the test is \(3+40\times 0.1575+1000\times 0.001187 = 10,760\)
What do you choose?
5.8 Nash Equilibrium
When multiple decision makers interact with each other, meaning the decision of one player changes the state of the “world” and thus affects the decision of another player, then we need to consider the notion of equilibrium. It is a central concept in economics and game theory. The most widely used type of equilibrium is the Nash equilibrium, named after John Nash, who introduced it in his 1950 paper “Equilibrium Points in N-Person Games.” It was popularized by the 1994 film “A Beautiful Mind,” which depicted Nash’s life and work.
It is defined as a set of strategies where no player can improve their payoff by unilaterally changing their strategy, assuming others keep their strategies constant. In other words, a Nash equilibrium is a set of strategies where no player has an incentive to deviate from their current strategy, given the strategies of the other players.
Here are a few examples of Nash equilibria: - Prisoner’s Dilemma: Two prisoners must decide whether to cooperate with each other or defect. The Nash equilibrium is for both to defect, even though they would be better off if they both cooperated. - Pricing Strategies: Firms in a market choose prices to maximize profits, taking into account their competitors’ pricing decisions. The equilibrium is the set of prices where no firm can increase profits by changing its price unilaterally. - Traffic Flow: Drivers choose routes to minimize travel time, based on their expectations of other drivers’ choices. The equilibrium is the pattern of traffic flow where no driver can reduce their travel time by choosing a different route.
Example 5.16 (Marble Game) Here is a subtle marble game where players have to call out (or present) either red or blue with different payoffs according to how things match. Two players \(A\) and \(B\) have both a red and a blue marble. They present one marble to each other. The payoff table is as follows:
If both present red, \(A\) wins $3.
If both present blue, \(A\) wins $1.
If the colors do not match, \(B\) wins $2
The question is whether it is better to be \(A\) or \(B\) or does it matter? Moreover, what kind of strategy should you play? A lot depends on how much credit you give your opponent. A lot of empirical research has studying the tit-for-tat strategy, where you cooperate until your opponent defects. Then you match his last response.
Nash equilibrium will also allow us to study the concept of a *randomized strategy (ie. picking a choice with a certain probability) which turns out to be optimal in many game theory problems.
First, assume that the players have a \(\frac{1}{2}\) probability of playing Red or Blue. Thus each player has the same expected payoff \(E(A) = \$1\)\[\begin{align*}
E(A) &= \frac{1}{4} \cdot 3 + \frac{1}{4} \cdot 1 =1 \\
E(B) &= \frac{1}{4} \cdot 2 + \frac{1}{4} \cdot 2 =1
\end{align*}\] We might go one step further and look at the risk (and measured by a standard deviation) and calculate the variances of each players payout \[\begin{align*}
Var (A) & = (1-1)^2 \cdot \frac{1}{4} +(3-1)^2 \cdot \frac{1}{4} + (0-1)^2 \cdot \frac{1}{2} = 1.5 \\
Var(B) & = 1^2 \cdot \frac{1}{2} + (2-1)^2 \cdot \frac{1}{2} = 1
\end{align*}\] Therefore, under this scenario, if you are risk averse, player \(B\) position is favored.
The matrix of probabilities with equally likely choices is given by
\(A,B\)
Probability
\(P( red, red )\)
(1/2)(1/2)=1/4
\(P( red, blue )\)
(1/2)(1/2)=1/4
\(P( blue, red )\)
(1/2)(1/2)=1/4
\(P( blue, blue )\)
(1/2)(1/2)=1/4
Now they is no reason to assume ahead of time that the players will decide to play \(50/50\) We will show that there’s a mixed strategy (randomized) that is a Nash equilibrium that is, both players won’t deviate from the strategy. We’ll prove that the following equilibrium happens:
\(A\) plays Red with probability 1/2 and blue 1/2
\(B\) plays Red with probability 1/4 and blue 3/4
In this case the expected payoff to playing Red equals that of playing Blue for each player. We can simply calculate: \(A\)’s expected payoff is 3/4 and \(B\)’s is $1 \[
E(A) = \frac{1}{8} \cdot 3 + \frac{3}{8} \cdot 1 = \frac{3}{4}
\] Moreover, \(E(B) =1\). AS \(E(B) > E(A)\), we see that \(B\) is the favored position. It is simple that if I know that you are going to play this strategy and vice-versa, neither of us will deviate from this strategy – hence the Nash equilibrium concept.
Nash equilibrium probabilities are: \(p=P( A \; red )= 1/2, p_1 = P( B \; red ) = 1/4\) with payout matrix
\(A,B\)
Probability
\(P( red, red )\)
(1/2)(1/4)=1/8
\(P( red, blue )\)
(1/2)(3/4)=3/8
\(P( blue, red )\)
(1/2)(1/4)=1/8
\(P( blue, blue )\)
(1/2)(3/4)=3/8
We have general payoff probabilities: \(p=P( A \; red ), p_1 = P( B \; red )\)
Much research has been directed to repeated games versus the one-shot game and is too large a topic to discuss further.
Equilibrium analysis helps predict the likely outcomes of strategic interactions, even when individuals are acting in their own self-interest. Further, we can use it to understand how markets function and how firms make pricing and production decisions or to design mechanisms (e.g., auctions, voting systems) that incentivize desired behavior and achieve efficient outcomes.
One major drawback is that equilibrium analysis relies on assumptions about rationality and common knowledge of preferences and strategies, which may not always hold in real-world situations. Furthermore, some games may have multiple equilibria, making it difficult to predict which one will be reached. The problem of dynamic strategies, when individuals may learn and adjust their strategies as they gain experience is hard.
5.9 Multi-Armed Bandits
When the number of options is large and the testing budget is limited, e.g. number of samples we can collect might not be enough to test multiple alternatives, we can use a different approach to A/B testing called multi-armed bandits. Although the math involved in analysis and design of the experiments is slightly more complected, the idea is simple. Instead of testing all alternatives at the same time, we test them sequentially. We start with a small number of alternatives and collect data. Based on the data we decide which alternative to test next. This way we can test more alternatives with the same number of samples. Thus, MABs allow us to explore and exploit simultaneously. Thus, MABs require that the outcome of each experiment is available immediately or with small enough delay to make a decision on the next experiment Scott (2015). On the other hand, MABs are more sample efficient and allow to find an optimal alternative faster. Thus, in the case when time is of essence and there as an opportunity cost associated with delaying the decision, MABs are a better choice.
Formally, there are \(K\) alternatives (arms) and each arm \(a\) is associated with a reward distribution \(v_a\), the value of this arm. The goal is to find the arm with the highest expected reward and accumulate the highest total reward in doing so. The reward distribution is unknown and we can only observe the reward after we select an arm \(a\) but we assume that we know the distribution \(f_a(y\mid \theta)\), where \(a\) is the arm index, \(y\) is the reward, and \(\theta\) is the set of unknown parameters to be learned. The value of arm \(v_a(\theta)\) is known, given \(\theta\). Here are a few examples:
In online advertisements, we have \(K\) possible ads to be shown and probability of user clicking is given by vector \(\theta = (\theta_1,\ldots,\theta_K)\) of success probabilities for \(K\) independent binomial models, with \(v_a(\theta) = \theta_a\). The goal is to find the ad with the highest click-through rate.
In website design, we have two design variables, the color of a button (red or blue) and its pixel size (27 or 40), we introduce two dummy variables \(x_c\) for color, \(x_s\) for size and the probability of user clicking is given by \[
\mathrm{logit} P(\text{click} \mid \theta) = \theta_0 + \theta_x x_c + \theta_s x_s + \theta_{cs}x_cx_s,
\] with \(v_a(\theta) = P(\text{click} \mid \theta)\).
A variation of the second example would include controlling for background variables, meaning adding covariates that correspond to variables that are not under our control. For example, we might want to control for the time of the day or the user’s location. This would allow us to estimate the effect of the design variables text and color while controlling for the background variables. Another variation is to replace the binary outcome variable with a continuous variable, such as the time spent on the website or the amount of money spent on the website or count variable. In this case we simply simple linear regression or another appropriate generalized linear model. Although at any given time, we might have our best guess about the values of parameters \(\hat \theta\), acting in a greedy way and choosing the arm with the highest expected reward \(\hat a = \arg\max_a v_a(\hat \theta)\), we might be missing out on a better alternative. The problem is that we are not sure about our estimates \(\hat \theta\) and we need to explore other alternatives. Thus, we need to balance exploration and exploitation. A widely used and oldest approach for managing the explore/exploit trade-off in a multi-armed bandit problem is Thompson sampling. The idea is to use Bayesian inference to estimate the posterior distribution of the parameters \(\theta\) and then sample from this distribution to select the next arm to test. The algorithm is as follows.
Initial Beliefs. For each arm \(k\) (\(k = 1,\ldots,K\)), define a prior belief about its reward distribution using a beta distribution with parameters \(\alpha_i\) and \(\beta_i\). These parameters represent the prior knowledge about the number of successes (\(\alpha_k\)) and failures (\(\beta_k\)) experienced with arm \(k\).
Sampling Parameters. For each arm \(k\), sample a reward \(\theta_k \sim Beta(\alpha_k, \beta_k)\) from the beta distribution. This simulates drawing a “potential” reward from the unknown true distribution of arm \(i\). A suboptimal greedy alternative is to select expected value of the parameter \(\hat \theta_k = E(\theta_k) =\alpha_k/(\alpha_k + \beta_k)\).
Choosing the Best Arm. Select the arm \(k\) with the highest sampled reward \(\hat \theta_k\): \[
a_t = \arg\max_i \hat \theta_k.
\]
Updating Beliefs. After observing the actual reward \(R_t\) for the chosen arm \(a_t\), update the parameters for that arm: \[
\alpha_i = \alpha_i + R_t, \quad \beta_i = \beta_i + (1 - R_t)
\] This update incorporates the new information gained from the actual reward into the belief about arm \(a_t\)’s distribution.
Repeat. Go back to step 2 and continue sampling, choosing, and updating until you reach a stopping point.
As the algorithm progresses, the posterior distributions of the arms are updated based on observed data, and arms with higher estimated success probabilities are favored for selection. Over time, Thompson Sampling adapts its beliefs and preferences, leading to better exploration and exploitation of arms.
It’s important to note that the effectiveness of Thompson Sampling depends on the choice of prior distributions and the updating process. The algorithm’s Bayesian nature allows it to naturally incorporate uncertainty and make informed decisions in the presence of incomplete information. The initial priors \((\alpha_i, \beta_i)\) can be set based on any available information about the arms, or as uniform distributions if no prior knowledge exists. This is a basic implementation of Thompson sampling. Variations exist for handling continuous rewards, incorporating side information, and adapting to non-stationary environments.
5.9.1 When to End Experiments
Steps 2 of the TS algorithm be replaced by calculating probability of an arm \(a\) being the best \(w_{at}\) and then choose the arm by sampling from the discrete distribution \(w_{1t},\ldots,w_{Kt}\). The probability of an arm \(a\) being the best is given by \[
w_{at} = P(a \text{ is optimal } \mid y^t) = \int P(a \text{ is optimal } \mid \theta) P(\theta \mid y^t) d\theta.
\] We can calculate the probabilities \(w_{at}\) using Monte Carlo. We can sample \(\theta^{(1)},\ldots,\theta^{(G)}\) from the posterior distribution \(p(\theta \mid y^t)\) and calculate the probability as \[
w_{at}\approx \dfrac{1}{G}\sum_{g=1}^G I(a = \arg\max_i v_i(\theta^{(g)})),
\] where \(I(\cdot)\) is the indicator function. This is simply the proportion of times the arm was the best in the \(G\) samples.
Although, using a single draw from posterior \(p(\theta \mid y^t)\) (as in the original algorithm) is equivalent to sampling proportional to \(w_{at}\) , the explicitly calculated \(w_{at}\) yields a useful statistic that can be used to decide on when to end the experiment.
We will use regret statistic to decide when to stop. Regret is the difference in values between the truly optimal arm and the arm that is apparently optimal at time. Although we cannot know the regret, it is unobservable, we can compute samples from its posterior distribution. We simulate the posterior distribution of the regret by sampling \(\theta^{(1)},\ldots,\theta^{(G)}\) from the posterior distribution \(p(\theta \mid y^t)\) and calculating the regret as \[
r^{(g)} = (v_a^*(\theta^{(g)}) - v_{a^*_t}(\theta^{(g)})),
\] Here \(a^*\) is the arm deemed best across all Monte Carlo draws and the first term is the value of the best arm within draw \(g\). We choose \(a^*_t\) as \[
a^*_t = \arg\max_a w_{at}.
\]
Often, it is convenient to measure the regret on the percent scale and then we use \[
r^{(g)} \leftarrow r^{(g)}/v_{a^*_t}(\theta^{(g)})
\]
Let’s demonstrate using a simulated data. The function below generates samples \(\theta^{(g)}\)
bandit =function(x,n,alpha =1,beta =1,ndraws =5000) {set.seed(17) # Kharlamov K <-length(x) # number of bandits prob <-matrix(nrow = ndraws,ncol = K) no = n - xfor (a in1:K) {# posterior draws for each arm prob[, a] =rbeta(ndraws,x[a] + alpha,no[a] + beta) } prob}
Say we have three arms with 20, 30, and 40 sessions that have generated 12, 20, and 30 conversions. We assume a uniform prior for each arm \(\theta_i \sim Beta(1,1)\) and generate 6 samples from the posterior of \(\theta \mid y^t\).
x =c(12,20,30)n =c(20, 30,40)prob =bandit(x, n,ndraws=6)
\(\theta_1\)
\(\theta_2\)
\(\theta_3\)
1
0.60
0.63
0.58
2
0.62
0.62
0.74
3
0.69
0.53
0.67
4
0.49
0.59
0.73
5
0.61
0.51
0.69
6
0.47
0.64
0.69
Now, we calculate the posterior probabilities \(w_{at} = P(a \text{ is optimal } \mid y^t)\) for each of the three arms
wat =table(factor(max.col(prob),levels =1:3))/6
1
2
3
0.17
0.17
0.67
Thus far, the third arm is the most likely to be optimal, with probability 67%. Now, we calculate the regret for each of the six draws from the posterior of \(\theta \mid y^t\).
regret = (apply(prob,1,max) - prob[,3])/prob[,3]
1
2
3
4
5
6
0.09
0
0.03
0
0
0
We compute value row by row by subtracting the largest element of that row from the element in column 3 (because arm 3 has the highest chance of being the optimal arm). All rows but 1 and 3 are zero. In the first row, the value is (0.63-0.58)/0.58 because column 2 is 0.05 larger than column 3. If we keep going down each row we get a distribution of values that we could plot in a histogram. Let’s generate one for a larger number of draws (10000).
The histogram of the value remaining in an experiment (regret). The vertical line is the 95th percentile, or the potential value remaining.
wat =table(factor(max.col(prob),levels =1:3))/10000
1
2
3
0.08
0.2
0.72
The histogram of the value remaining in an experiment (regret). The vertical line is the 95th percentile, or the potential value remaining.
Arm 3 has a 72% probability of being the best arm, so the value of switching away from arm 3 is zero in 72% of the cases. The 95th percentile of the value distribution is the “potential value remaining” (CvR) in the experiment, which in this case works out to be about .16.
quantile(regret,0.95)
95%
0.17
You interpret this number as “We’re still unsure about the CvR for arm 3, but whatever it is, one of the other arms might beat it by as much as 16%.”
Google Analytics, for example, “ends the experiment when there’s at least a 95% probability that the value remaining in the experiment is less than 1% of the champion’s conversion rate. That’s a 1% improvement, not a one percentage point improvement. So if the best arm has a conversion rate of 4%, then we end the experiment if the value remaining in the experiment is less than .04 percentage points of CvR”.
5.9.2 Contextual Bandits
Traditional multi-armed bandit models, like the binomial model, assume independent observations with fixed reward probabilities. This works well when rewards are consistent across different groups and times. However, for situations with diverse user bases or fluctuating activity patterns, such as international audiences or browsing behavior, this assumption can be misleading.
For instance, companies with a global web presence may experience temporal effects as markets in Asia, Europe, and the Americas become active at different times of the day. Additionally, user behavior can change based on the day of the week, with people engaging in different browsing patterns and purchase behaviors. For example, individuals may research expensive purchases during work hours but make actual purchases on weekends.
Consider an experiment with two arms, A and B. Arm A performs slightly better during the weekdays when users browse but don’t make purchases, while Arm B excels during the weekends when users are more likely to make purchases. If there is a substantial amount of traffic, the binomial model might prematurely conclude that Arm A is the superior option before any weekend traffic is observed. This risk exists regardless of whether the experiment is conducted as a bandit or a traditional experiment. However, bandit experiments are more susceptible to this issue because they typically run for shorter durations.
To mitigate the risk of being misled by distinct sub-populations, two methods can be employed. If the specific sub-populations are known in advance or if there is a proxy for them, such as geographically induced temporal patterns, the binomial model can be adapted to a logistic regression model. This modification allows for a more nuanced understanding of the impact of different factors on arm performance, helping to account for variations in sub-population behavior and temporal effects. \[
\mathrm{logit} P(\text{click}_a \mid \theta, x) = \theta_{0a} + \beta^Tx,
\] where \(x\) that describe the circumstances or context of the observation. The success probability for selecting arm \(a\) under the context \(x\) is represented as \(P(\text{click}_a \mid \theta, x)\). Each arm \(a\) has its own specific coefficient denoted as \(\beta_{0a}\) with one arm’s coefficient set to zero as a reference point. Additionally, there is another set of coefficients represented as \(\beta\) that are associated with the contextual data and are learned as part of the model. The value function can then be \[
v_a(\theta) = \mathrm{logit}^{-1}(\beta_{0a}).
\]
If we lack knowledge about the crucial contexts, one option is to make the assumption that contexts are generated randomly from a context distribution. This approach is often exemplified by the use of a hierarchical model like the beta-binomial model. \[\begin{align*}
\theta_{at} &\sim Beta(\alpha_a,\beta_a)\\
\text{click}_a \mid \theta &\sim Binomial(\theta_{at}),
\end{align*}\] where \(\theta = \{\alpha_a,\beta_a ~:~ a = 1,\ldots,K \}\), with value function \(v_a(\theta) = \alpha_a/\beta_a\)
5.9.3 Summary of MAB Experimentation
1. Design:
Define your arms: Identify the different options you want to evaluate, like different website layouts, pricing strategies, or marketing campaigns.
Choose a bandit algorithm: Different algorithms balance exploration and exploitation in various ways. Popular choices include Epsilon-greedy, Thompson Sampling, and Upper Confidence Bound (UCB).
Set your parameters: Configure the algorithm parameters based on your priorities and expected uncertainty. For example, a higher exploration rate encourages trying new arms earlier.
Randomize allocation: Assign users to arms randomly, ensuring unbiased data collection.
2. Analysis:
Track rewards: Define and measure the reward metric for each arm, such as clicks, conversions, or profit.
Monitor performance: Regularly analyze the cumulative reward and arm selection probabilities to see which arms are performing well and how the allocation strategy is adapting.
Statistical tools: Use statistical tests like confidence intervals or Bayesian methods to compare performance between arms and assess the significance of findings.
Adaptive adjustments: Adapt the experiment based on ongoing analysis. You might adjust algorithm parameters, stop arms with demonstrably poor performance, or introduce new arms.
3. Practical Tips:
Start with a small pool of arms: Avoid information overload by testing a manageable number of options initially.
Set a clear stopping criterion: Decide when to end the experiment based on a predetermined budget, time limit, or desired level of confidence in the results.
Consider ethical considerations: Ensure user privacy and informed consent if the experiment involves personal data or user experience changes.
Interpret results in context: Remember that MAB results are specific to the tested conditions and might not generalize perfectly to other contexts.
By following these steps and utilizing available resources, you can design and analyze effective MAB experiments to optimize your decision-making in various scenarios. Remember to adapt your approach based on your specific goals and context to maximize the benefits of this powerful technique.
5.10 Q-Learning
5.11 Reinforcement Learning
Scott, Steven L. 2015. “Multi-Armed Bandit Experiments in the Online Service Economy.”Applied Stochastic Models in Business and Industry 31 (1): 37–45.